Publications
2025
-
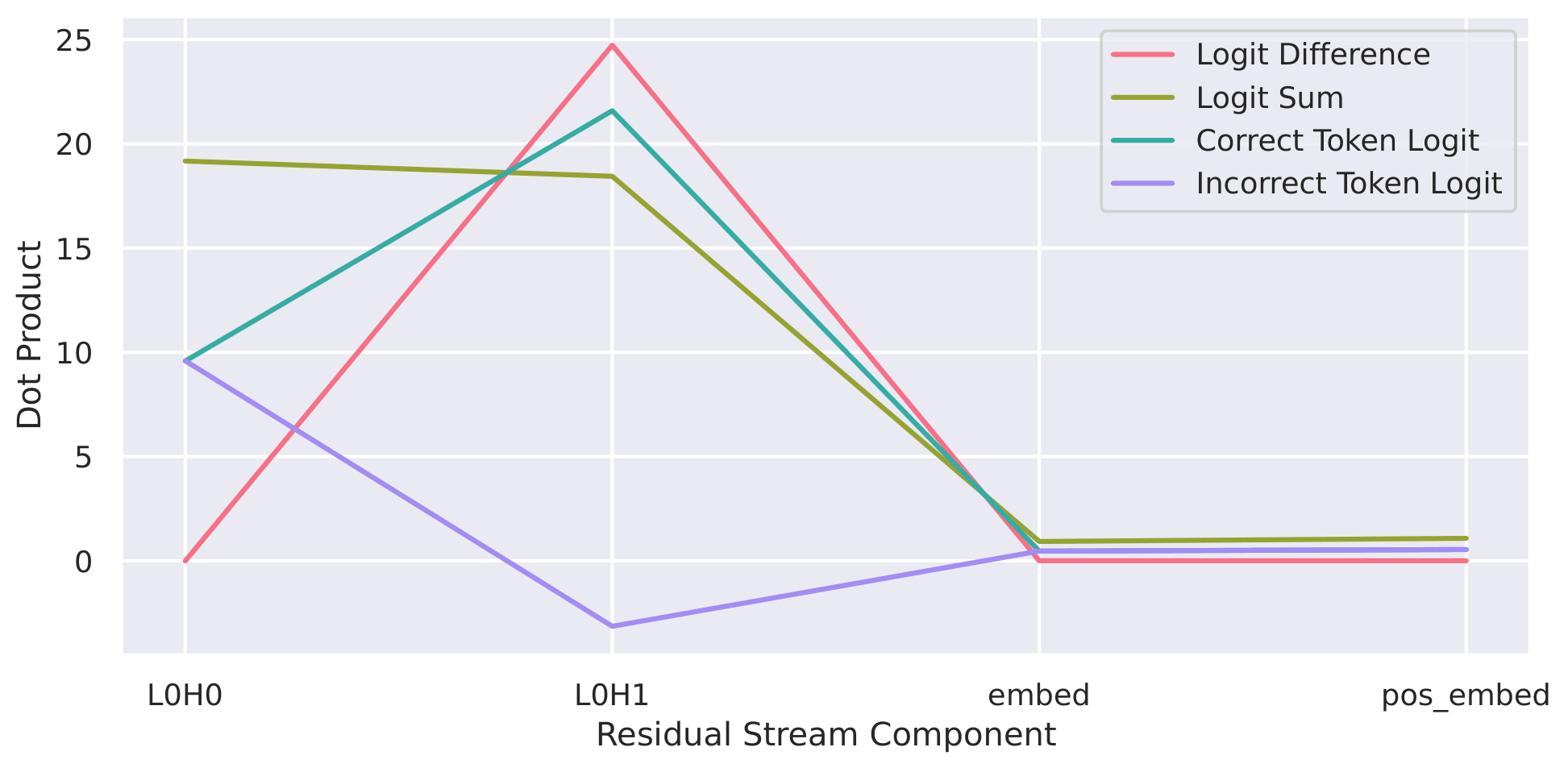 Emergence of Minimal Circuits for Indirect Object Identification in Attention-Only TransformersRabin AdhikariCoRR, Oct 2025
Emergence of Minimal Circuits for Indirect Object Identification in Attention-Only TransformersRabin AdhikariCoRR, Oct 2025Mechanistic interpretability aims to reverse-engineer large language models (LLMs) into human-understandable computational circuits. However, the complexity of pretrained models often obscures the minimal mechanisms required for specific reasoning tasks. In this work, we train small, attention-only transformers from scratch on a symbolic version of the Indirect Object Identification (IOI) task – a benchmark for studying coreference – like reasoning in transformers. Surprisingly, a single-layer model with only two attention heads achieves perfect IOI accuracy, despite lacking MLPs and normalization layers. Through residual stream decomposition, spectral analysis, and embedding interventions, we find that the two heads specialize into additive and contrastive subcircuits that jointly implement IOI resolution. Furthermore, we show that a two-layer, one-head model achieves similar performance by composing information across layers through query-value interactions. These results demonstrate that task-specific training induces highly interpretable, minimal circuits, offering a controlled testbed for probing the computational foundations of transformer reasoning.
@article{DBLP:journals/corr/abs-2510-25013, author = {Adhikari, Rabin}, title = {Emergence of Minimal Circuits for Indirect Object Identification in Attention-Only Transformers}, journal = {CoRR}, volume = {abs/2510.25013}, month = oct, year = {2025}, url = {https://doi.org/10.48550/arXiv.2510.25013}, doi = {10.48550/ARXIV.2510.25013}, eprinttype = {arXiv}, timestamp = {Sun, 16 Nov 2025 10:09:04 +0100}, biburl = {https://dblp.org/rec/journals/corr/abs-2510-25013.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, }
2024
- ACCV (Oral)
 TuneVLSeg: Prompt Tuning Benchmark for Vision-Language Segmentation ModelsRabin Adhikari, Safal Thapaliya, Manish Dhakal, and Bishesh KhanalIn Computer Vision - ACCV 2024 - 17th Asian Conference on Computer Vision, Hanoi, Vietnam, December 8-12, 2024, Proceedings, Part III, Dec 2024
TuneVLSeg: Prompt Tuning Benchmark for Vision-Language Segmentation ModelsRabin Adhikari, Safal Thapaliya, Manish Dhakal, and Bishesh KhanalIn Computer Vision - ACCV 2024 - 17th Asian Conference on Computer Vision, Hanoi, Vietnam, December 8-12, 2024, Proceedings, Part III, Dec 2024Vision-Language Models (VLMs) have shown impressive performance in vision tasks, but adapting them to new domains often requires expensive fine-tuning. Prompt tuning techniques, including textual, visual, and multimodal prompting, offer efficient alternatives by leveraging learnable prompts. However, their application to Vision-Language Segmentation Models (VLSMs) and evaluation under significant domain shifts remain unexplored. This work presents an open-source benchmarking framework, TuneVLSeg, to integrate various unimodal and multimodal prompt tuning techniques into VLSMs, making prompt tuning usable for downstream segmentation datasets with any number of classes. We test various prompt tuning on 8 diverse medical datasets, including 3 radiology datasets (breast tumor, echocardiograph, chest X-ray pathologies) and 5 non-radiology datasets (polyp, ulcer, skin cancer), and two natural domain segmentation datasets. Our study found that textual prompt tuning struggles under significant domain shifts, from natural-domain images to medical data. Furthermore, visual prompt tuning, with fewer hyperparameters than multimodal prompt tuning, often achieves performance competitive to multimodal approaches, making it a valuable first attempt. Our work advances the understanding and applicability of different prompt-tuning techniques for robust domain-specific segmentation.
@inproceedings{DBLP:conf/accv/AdhikariTDK24, author = {Adhikari, Rabin and Thapaliya, Safal and Dhakal, Manish and Khanal, Bishesh}, editor = {Cho, Minsu and Laptev, Ivan and Tran, Du and Yao, Angela and Zha, Hongbin}, title = {TuneVLSeg: Prompt Tuning Benchmark for Vision-Language Segmentation Models}, booktitle = {Computer Vision - {ACCV} 2024 - 17th Asian Conference on Computer Vision, Hanoi, Vietnam, December 8-12, 2024, Proceedings, Part {III}}, series = {Lecture Notes in Computer Science}, volume = {15474}, pages = {44--62}, publisher = {Springer}, month = dec, year = {2024}, doi = {10.1007/978-981-96-0908-6\_3}, timestamp = {Wed, 08 Jan 2025 21:12:47 +0100}, biburl = {https://dblp.org/rec/conf/accv/AdhikariTDK24.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, } - MICCAI (Poster)
 VLSM-Adapter: Finetuning Vision-Language Segmentation Efficiently with Lightweight BlocksManish Dhakal, Rabin Adhikari, Safal Thapaliya, and Bishesh KhanalIn Medical Image Computing and Computer Assisted Intervention - MICCAI 2024 - 27th International Conference, Marrakesh, Morocco, October 6-10, 2024, Proceedings, Part IX, Oct 2024
VLSM-Adapter: Finetuning Vision-Language Segmentation Efficiently with Lightweight BlocksManish Dhakal, Rabin Adhikari, Safal Thapaliya, and Bishesh KhanalIn Medical Image Computing and Computer Assisted Intervention - MICCAI 2024 - 27th International Conference, Marrakesh, Morocco, October 6-10, 2024, Proceedings, Part IX, Oct 2024Foundation Vision-Language Models (VLMs) trained using large-scale open-domain images and text pairs have recently been adapted to develop Vision-Language Segmentation Models (VLSMs) that allow providing text prompts during inference to guide image segmentation. If robust and powerful VLSMs can be built for medical images, it could aid medical professionals in many clinical tasks where they must spend substantial time delineating the target structure of interest. VLSMs for medical images resort to fine-tuning base VLM or VLSM pretrained on open-domain natural image datasets due to fewer annotated medical image datasets; this fine-tuning is resource-consuming and expensive as it usually requires updating all or a significant fraction of the pretrained parameters. Recently, lightweight blocks called adapters have been proposed in VLMs that keep the pretrained model frozen and only train adapters during fine-tuning, substantially reducing the computing resources required. We introduce a novel adapter, VLSM-Adapter, that can fine-tune pretrained vision-language segmentation models using transformer encoders. Our experiments in widely used CLIP-based segmentation models show that with only 3 million trainable parameters, the VLSM-Adapter outperforms state-of-the-art and is comparable to the upper bound end-to-end fine-tuning.
@inproceedings{DBLP:conf/miccai/DhakalATK24, author = {Dhakal, Manish and Adhikari, Rabin and Thapaliya, Safal and Khanal, Bishesh}, editor = {Linguraru, Marius George and Dou, Qi and Feragen, Aasa and Giannarou, Stamatia and Glocker, Ben and Lekadir, Karim and Schnabel, Julia A.}, title = {VLSM-Adapter: Finetuning Vision-Language Segmentation Efficiently with Lightweight Blocks}, booktitle = {Medical Image Computing and Computer Assisted Intervention - {MICCAI} 2024 - 27th International Conference, Marrakesh, Morocco, October 6-10, 2024, Proceedings, Part {IX}}, series = {Lecture Notes in Computer Science}, volume = {15009}, pages = {712--722}, publisher = {Springer}, month = oct, year = {2024}, doi = {10.1007/978-3-031-72114-4\_68}, timestamp = {Thu, 17 Apr 2025 16:28:04 +0200}, biburl = {https://dblp.org/rec/conf/miccai/DhakalATK24.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, } - MIDL (Oral)
 Exploring Transfer Learning in Medical Image Segmentation using Vision-Language ModelsKanchan Poudel*, Manish Dhakal*, Prasiddha Bhandari*, Rabin Adhikari*, Safal Thapaliya*, and 1 more authorIn Medical Imaging with Deep Learning, 3-5 July 2024, Paris, France, Jul 2024
Exploring Transfer Learning in Medical Image Segmentation using Vision-Language ModelsKanchan Poudel*, Manish Dhakal*, Prasiddha Bhandari*, Rabin Adhikari*, Safal Thapaliya*, and 1 more authorIn Medical Imaging with Deep Learning, 3-5 July 2024, Paris, France, Jul 2024Medical image segmentation allows quantifying target structure size and shape, aiding in disease diagnosis, prognosis, surgery planning, and comprehension. Building upon recent advancements in foundation Vision-Language Models (VLMs) from natural image-text pairs, several studies have proposed adapting them to Vision-Language Segmentation Models (VLSMs) that allow using language text as an additional input to segmentation models. Introducing auxiliary information via text with human-in-the-loop prompting during inference opens up unique opportunities, such as open vocabulary segmentation and potentially more robust segmentation models against out-of-distribution data. Although transfer learning from natural to medical images has been explored for image-only segmentation models, the joint representation of vision-language in segmentation problems remains underexplored. This study introduces the first systematic study on transferring VLSMs to 2D medical images, using carefully curated 11 datasets encompassing diverse modalities and insightful language prompts and experiments. Our findings demonstrate that although VLSMs show competitive performance compared to image-only models for segmentation after finetuning in limited medical image datasets, not all VLSMs utilize the additional information from language prompts, with image features playing a dominant role. While VLSMs exhibit enhanced performance in handling pooled datasets with diverse modalities and show potential robustness to domain shifts compared to conventional segmentation models, our results suggest that novel approaches are required to enable VLSMs to leverage the various auxiliary information available through language prompts.
@inproceedings{DBLP:conf/midl/PoudelDBATK24, author = {Poudel, Kanchan and Dhakal, Manish and Bhandari, Prasiddha and Adhikari, Rabin and Thapaliya, Safal and Khanal, Bishesh}, editor = {Burgos, Ninon and Petitjean, Caroline and Vakalopoulou, Maria and Christodoulidis, Stergios and Coup{\'{e}}, Pierrick and Delingette, Herv{\'{e}} and Lartizien, Carole and Mateus, Diana}, title = {Exploring Transfer Learning in Medical Image Segmentation using Vision-Language Models}, booktitle = {Medical Imaging with Deep Learning, 3-5 July 2024, Paris, France}, series = {Proceedings of Machine Learning Research}, volume = {250}, pages = {1142--1165}, publisher = {{PMLR}}, month = jul, year = {2024}, url = {https://proceedings.mlr.press/v250/poudel24a.html}, timestamp = {Mon, 17 Mar 2025 07:57:06 +0100}, biburl = {https://dblp.org/rec/conf/midl/PoudelDBATK24.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, }
2023
- ASMUS @ MICCAI
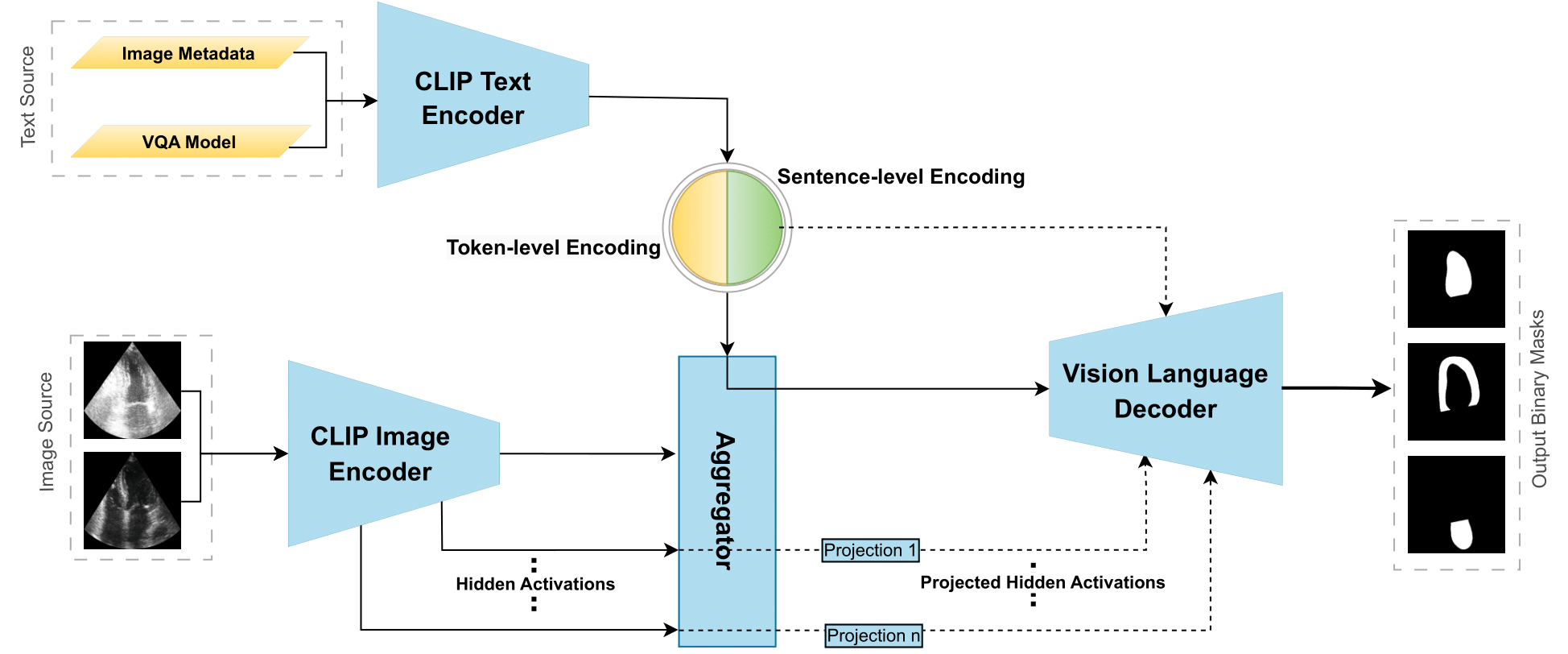 Synthetic Boost: Leveraging Synthetic Data for Enhanced Vision-Language Segmentation in EchocardiographyRabin Adhikari*, Manish Dhakal*, Safal Thapaliya*, Kanchan Poudel, Prasiddha Bhandari, and 1 more authorIn Simplifying Medical Ultrasound - 4th International Workshop, ASMUS 2023, Held in Conjunction with MICCAI 2023, Vancouver, BC, Canada, October 8, 2023, Proceedings, Oct 2023
Synthetic Boost: Leveraging Synthetic Data for Enhanced Vision-Language Segmentation in EchocardiographyRabin Adhikari*, Manish Dhakal*, Safal Thapaliya*, Kanchan Poudel, Prasiddha Bhandari, and 1 more authorIn Simplifying Medical Ultrasound - 4th International Workshop, ASMUS 2023, Held in Conjunction with MICCAI 2023, Vancouver, BC, Canada, October 8, 2023, Proceedings, Oct 2023Accurate segmentation is essential for echocardiography-based assessment of cardiovascular diseases (CVDs). However, the variability among sonographers and the inherent challenges of ultrasound images hinder precise segmentation. By leveraging the joint representation of image and text modalities, Vision-Language Segmentation Models (VLSMs) can incorporate rich contextual information, potentially aiding in accurate and explainable segmentation. However, the lack of readily available data in echocardiography hampers the training of VLSMs. In this study, we explore using synthetic datasets from Semantic Diffusion Models (SDMs) to enhance VLSMs for echocardiography segmentation. We evaluate results for two popular VLSMs (CLIPSeg and CRIS) using seven different kinds of language prompts derived from several attributes, automatically extracted from echocardiography images, segmentation masks, and their metadata. Our results show improved metrics and faster convergence when pretraining VLSMs on SDM-generated synthetic images before finetuning on real images.
@inproceedings{DBLP:conf/miccai/AdhikariDTPBK23, author = {Adhikari, Rabin and Dhakal, Manish and Thapaliya, Safal and Poudel, Kanchan and Bhandari, Prasiddha and Khanal, Bishesh}, editor = {Kainz, Bernhard and Noble, J. Alison and Schnabel, Julia A. and Khanal, Bishesh and M{\"{u}}ller, Johanna P. and Day, Thomas G.}, title = {Synthetic Boost: Leveraging Synthetic Data for Enhanced Vision-Language Segmentation in Echocardiography}, booktitle = {Simplifying Medical Ultrasound - 4th International Workshop, {ASMUS} 2023, Held in Conjunction with {MICCAI} 2023, Vancouver, BC, Canada, October 8, 2023, Proceedings}, series = {Lecture Notes in Computer Science}, volume = {14337}, pages = {89--99}, publisher = {Springer}, month = oct, year = {2023}, doi = {10.1007/978-3-031-44521-7\_9}, timestamp = {Fri, 27 Oct 2023 20:40:19 +0200}, biburl = {https://dblp.org/rec/conf/miccai/AdhikariDTPBK23.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, }
2022
- SMM4H @ COLING
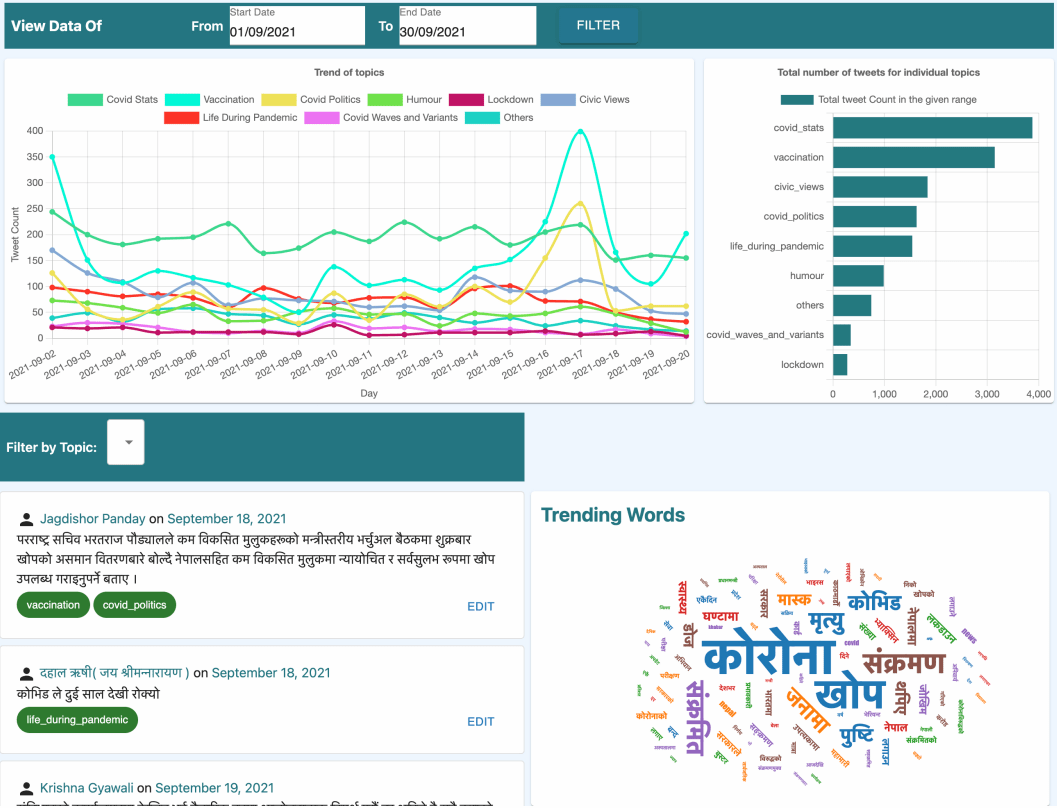 COVID-19-related Nepali Tweets Classification in a Low Resource SettingRabin Adhikari, Safal Thapaliya, Nirajan Basnet, Samip Poudel, Aman Shakya, and 1 more authorIn Proceedings of The Seventh Workshop on Social Media Mining for Health Applications, Workshop & Shared Task, SMM4H@COLING 2022, Gyeongju, Republic of Korea, October 12 - 17, 2022, Oct 2022
COVID-19-related Nepali Tweets Classification in a Low Resource SettingRabin Adhikari, Safal Thapaliya, Nirajan Basnet, Samip Poudel, Aman Shakya, and 1 more authorIn Proceedings of The Seventh Workshop on Social Media Mining for Health Applications, Workshop & Shared Task, SMM4H@COLING 2022, Gyeongju, Republic of Korea, October 12 - 17, 2022, Oct 2022Billions of people across the globe have been using social media platforms in their local languages to voice their opinions about the various topics related to the COVID-19 pandemic. Several organizations, including the World Health Organization, have developed automated social media analysis tools that classify COVID-19-related tweets into various topics. However, these tools that help combat the pandemic are limited to very few languages, making several countries unable to take their benefit. While multi-lingual or low-resource language-specific tools are being developed, they still need to expand their coverage, such as for the Nepali language. In this paper, we identify the eight most common COVID-19 discussion topics among the Twitter community using the Nepali language, set up an online platform to automatically gather Nepali tweets containing the COVID-19-related keywords, classify the tweets into the eight topics, and visualize the results across the period in a web-based dashboard. We compare the performance of two state-of-the-art multi-lingual language models for Nepali tweet classification, one generic (mBERT) and the other Nepali language family-specific model (MuRIL). Our results show that the models’ relative performance depends on the data size, with MuRIL doing better for a larger dataset.
@inproceedings{DBLP:conf/coling/AdhikariTBPSK22, author = {Adhikari, Rabin and Thapaliya, Safal and Basnet, Nirajan and Poudel, Samip and Shakya, Aman and Khanal, Bishesh}, editor = {Gonzalez{-}Hernandez, Graciela and Weissenbacher, Davy}, title = {COVID-19-related Nepali Tweets Classification in a Low Resource Setting}, booktitle = {Proceedings of The Seventh Workshop on Social Media Mining for Health Applications, Workshop {\&} Shared Task, SMM4H@COLING 2022, Gyeongju, Republic of Korea, October 12 - 17, 2022}, pages = {209--215}, publisher = {Association for Computational Linguistics}, month = oct, year = {2022}, url = {https://aclanthology.org/2022.smm4h-1.52}, timestamp = {Sat, 30 Sep 2023 09:37:31 +0200}, biburl = {https://dblp.org/rec/conf/coling/AdhikariTBPSK22.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, } - JIIP
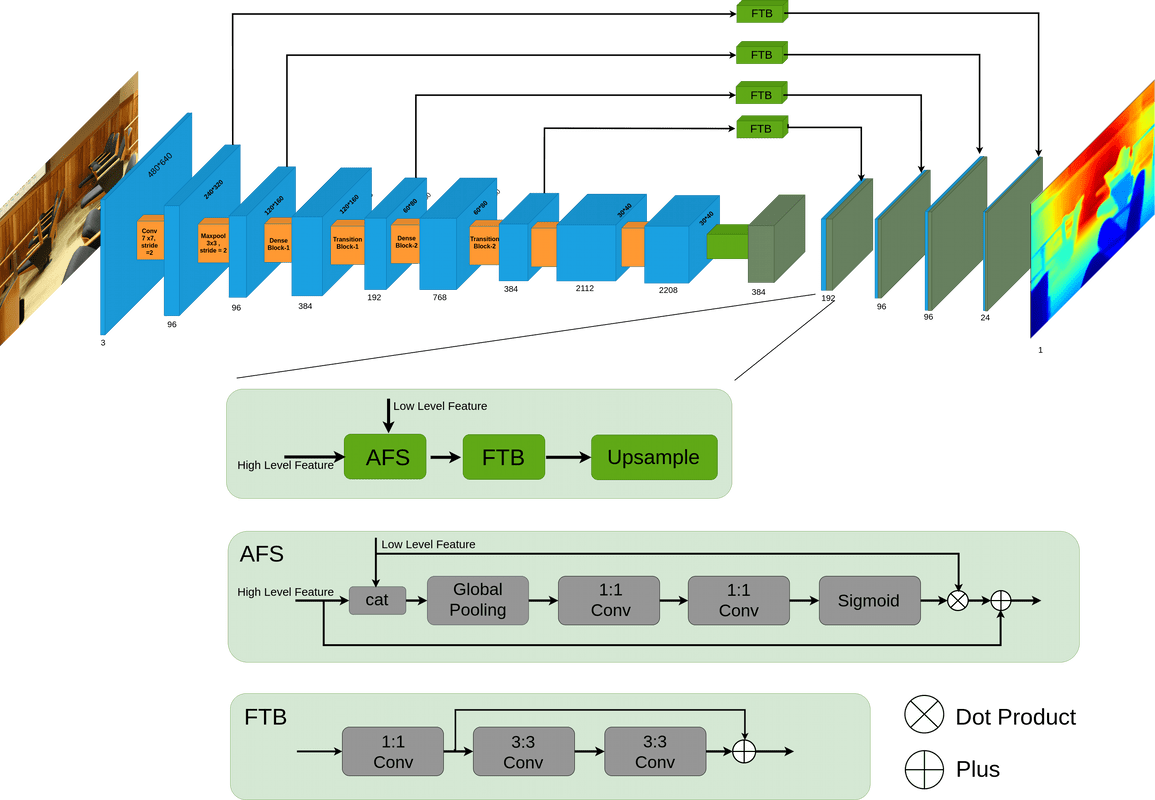 Monocular Depth Estimation using a Multi-grid Attention-based ModelSangam Man Buddhacharya, Rabin Adhikari, Nischal Maharjan, and Sanjeeb Prasad PandayJournal of Innovative Image Processing, Aug 2022
Monocular Depth Estimation using a Multi-grid Attention-based ModelSangam Man Buddhacharya, Rabin Adhikari, Nischal Maharjan, and Sanjeeb Prasad PandayJournal of Innovative Image Processing, Aug 2022With the increased use of depth information in computer vision, monocular depth estimation has been an emerging field of study. It is a challenging task where many deep convolutional neural network-based methods have been used for depth prediction. The problem with most of these approaches is that they use a repeated combination of max-pooling and striding in an encoder, which reduces spatial resolution. In addition, these approaches use information from all the channels directly from the encoder, which is prone to noise. Addressing these issues, we present a multigrid attention-based densenet-161 model. It consists of a multigrid densenet-161 encoder that increases the spatial resolution and an attention-based decoder to select the important information from low-level features. We achieved absolute relative error (Absrel) of 0.109 and 0.0724 on NYU v2 and KITTI, dataset respectively. Our proposed method exceeded most evaluation measures with fewer parameters compared to the state-ofthe-art on standard benchmark datasets. We produce a dense depth map from a single RGB image which can be used to create a dense point cloud. The anticipated depth map is accurate and smooth, which can be used in several applications.
@article{buddhacharya2022monocular, title = {Monocular Depth Estimation using a Multi-grid Attention-based Model}, author = {Buddhacharya, Sangam Man and Adhikari, Rabin and Maharjan, Nischal and Panday, Sanjeeb Prasad}, journal = {Journal of Innovative Image Processing}, volume = {4}, number = {3}, pages = {127--146}, month = aug, year = {2022}, publisher = {IRO Journals}, doi = {10.36548/jiip.2022.3.001}, }